The ratio of time spent reading(code) vs. writing is well over 10:1…if you want your code to be easy to write, make it easy to read. – Robert C. Martin (Clean Code)
At LiteBreeze, our focus is mainly on complex web applications that cannot be built using a Content management system. Such an application always contains thousands of lines of code and is built by teams of different sizes.
From a developer perspective, we expect our applications to meet all the below qualities:
Meeting all these qualities will also result in faster development and release cycles.
Code quality has a huge impact on big long-term projects. Our ERP portal is a great example of an extreme case: inexperienced staff had built the old foundation back in 2010 and it took the new team over 100 man-hours just to understand it, make it run on a new server and clean up the code.
These hours could have been saved if the original code had been well-written.
Another reason to perfect code is that big high-value clients will want to check code samples before hiring us. They will be very selective and require perfection. So we need to make sure that we can always present the codebase for tough scrutiny by an expert from a prospective client’s team.
Software engineering is not easy, it takes great effort to build good quality software. This is why Code quality is one of the core principles at LiteBreeze.
“Given enough eyeballs, all bugs are shallow” – Eric S Raymond (Linus’s Law)
Code review or peer review is a software quality assurance practice in which one or more people review the code you’ve developed. You must ensure that all the code is reviewed before it is merged to the main branch of the source code control system.
Code review helps us find bugs early and also helps in transferring knowledge between team members. We use pull requests for performing code reviews.
Further reading
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.” – Martin Fowler
Code refactoring is the process of restructuring existing computer code without changing its external behaviour. We refactor code to improve its design and structure so that it’s readable, maintainable and extensible.
Continuously refactoring the code is important in long-term projects, it will help us to incorporate new features into the application without much effort.
Further reading
Test automation is the process of using dedicated software to automate the execution of tests and to compare the actual and expected outcomes.
It’s quite common that you sometimes overlook the testing phase and let bugs slip through to production. This is mostly because you may find it difficult to perform the testing of all the affected features.
With automated testing this is no longer a problem, you can execute the tests without any effort, and it will only take a few minutes to execute all the test cases.
Tests can act as documentation and help us easily refactor the code without worrying about breaking any existing functionalities.
Unit tests are automated tests written to ensure that a particular section of an application meets its expected outcomes. Each test case is executed in isolation and substitutes such as mocks, fakes and stubs are used to assist the testing.
Further reading
The name of a variable, function, or class, should answer all the big questions. It should tell you why it exists, what it does, and how it is used. If a name requires a comment, then the name does not reveal its intent. – Robert C Martin (Clean code)
Always choose clear and understandable names for variables/functions/classes. The names you choose should be also searchable, so we can easily find its usage across the codebase.
Do not be afraid to choose long names if you have to. We all rely on IDEs for auto-completing the symbol names, so choosing short names just to make typing easier is not worth it.
Programming is a social activity. A great deal of time is invested in discussing the code with peers. So, avoid variable names that are hard to pronounce. If you can’t pronounce it, you can’t discuss it with them. No one will be able to remember it, aside from the writer themselves.
Use noun or noun phrase names for classes and objects. Methods and functions should have verb or verb phrases as their name.
Pick one word per concept, it will be very confusing if words such as find, fetch, retrieve or get are used interchangeably for naming methods that are used to access something. Sticking with one word will make it easy to memorize the names.
A “comment” is a failure to express yourself in code. If you fail, then write a comment, but try not to fail. – Robert C Martin
Always try to express yourself in code. We needn’t comment if we choose proper variable/function/class names.
It is sometimes useful to add a comment for explaining complex parts such as regular expressions(regex), so the readers don’t have to evaluate it inside their own minds every time. But, even in such cases, there might be a better alternate. For e.g.We can store the regex in a variable and choose a descriptive name for it to communicate what the expression is supposed to match. In case you choose to comment, you must ensure that the comment is properly updated when the regular expression or code that is associated with it changes.
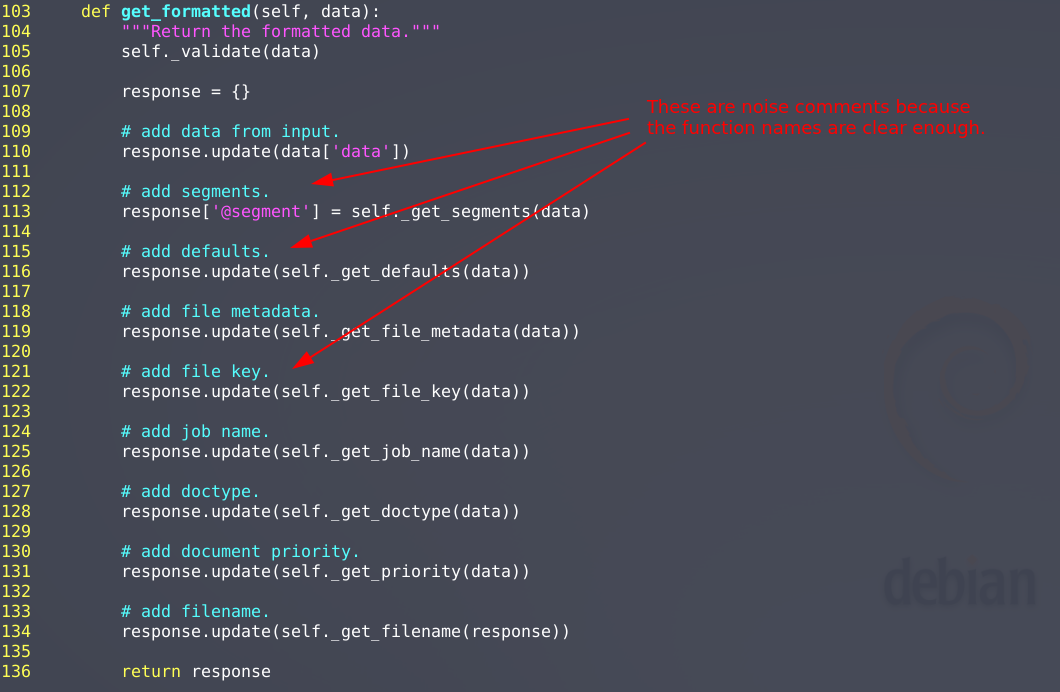
Avoid noise comments like these, which do not add anything to the statements they try to explain.
Commit only clean code and required files (set ignore options on non-required files such as form uploaded files, IDE configurations, log files etc). It should be possible to do a code review on a committed code. Don’t upload duplicates of libraries for various panels and so on. Commit as few unnecessary lines of code as possible.
The recommended commit message structure has two parts, the first one is a short and single line subject and the second one is a detailed and multi-line body.
The commit body may contain detailed description about the commit and your time entries.
Subject part is mandatory, however, most of your commit messages will have the body part because we will have to include the time entries. If a commit contains very trivial changes such as fixing a typo, then you may skip the body part.
It is critical that the subject and body are separated by a blank line.
The rationale behind some of these decisions can be found here.
Example commit messages are shown here.
An optional commit template has been set up to follow the recommendation. Here is the snippet (private link – for internal reference only) for it. It also contains a script to configure the template globally and a hook for validating the commit subject when performing the commits.
The subject must clearly summarize the changes in the commit and shouldn’t end with a full stop.
Limit the length of the subject line to a maximum of 50 chars and avoid generic text like “Pull request comment fixes”, “Partial commit” or “Code quality fixes” etc. as the commit subject.
Aim to use imperative mood instead of indicative mood in the subject line. Instead of saying “Fixed typo in overview section” say “Fix typo in overview section”.
The commit subject must be in sentence case.
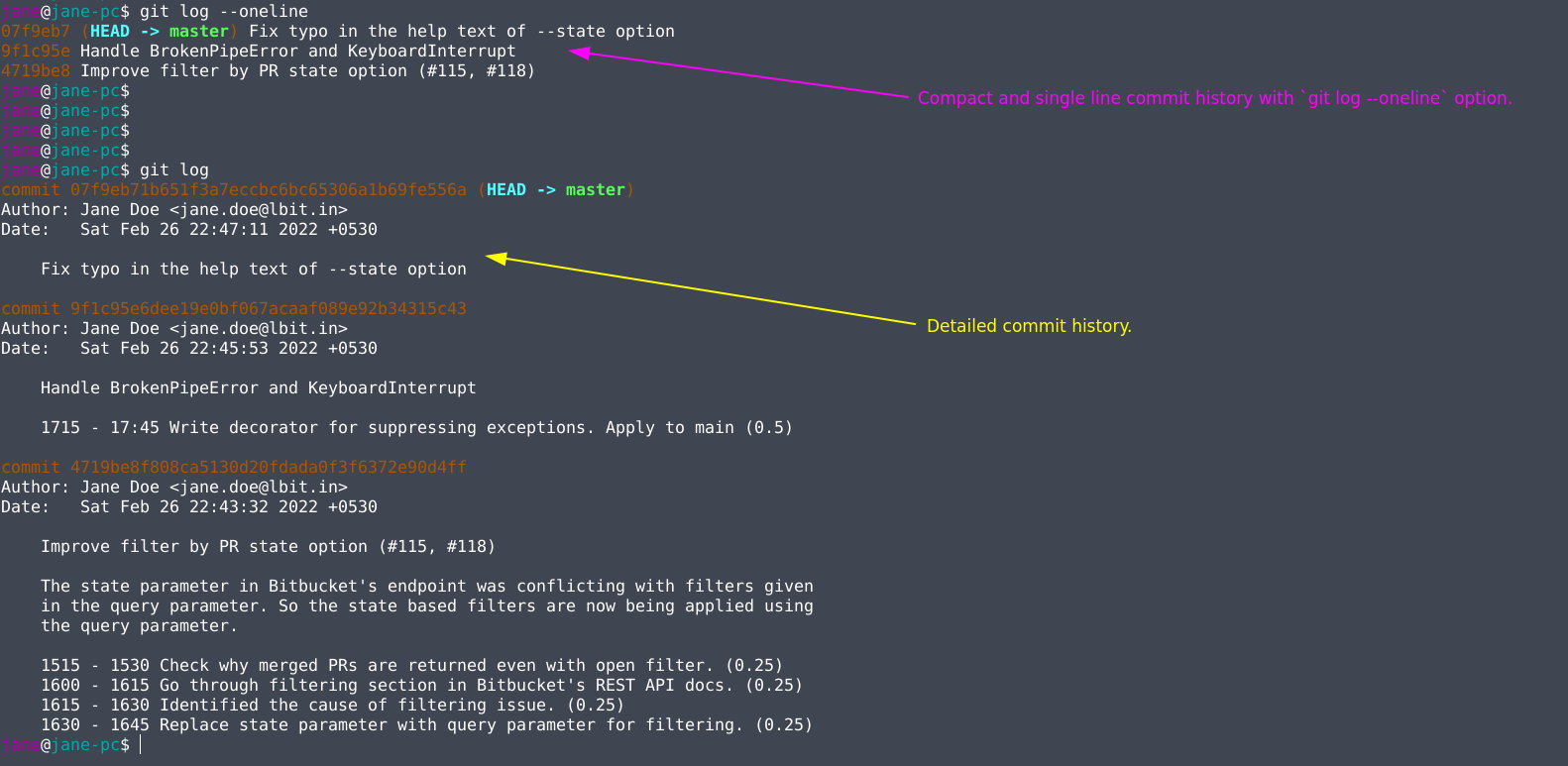
The advantage of having a subject part is that we can easily review the commit log using the git log --oneline command as shown here. It will also improve the readability of commit messages in the source code hosting services such as Bitbucket or Gitlab as they will only display the first line in listings.
Issue tracker references
Put any issue tracker references at the end of the commit subject line. Use the format “<commit subject> (<issue-id1>, <issue-id2>)”, placement of spaces, brackets and comma are important.
If you are referencing Bitbucket issues, prefix the issue ids with a hash sign (#). This is not needed for Jira issue ids.
It may contain different sections as given below.
Optional description
An optional description can be provided if you want to provide details on what are the changes involved and also why it was done. The description can be split into multiple paragraphs and may also contain bulleted or numbered lists.
Time entries
Time entries related to the commit can be added to the end of the commit message. This part must be separated using another blank line.
Bugs and logic flaws are the primary causes of commonly exploited software vulnerabilities.
Never trust user input, i.e. always validate user input before persisting to the datastore. This will make sure that stored information is correct and useful. Always perform server-side validation, even if client-side validation is present.
An example could be if there are checks to prevent one control panel user from accessing data of another control panel user (by manipulating request variables).
Another would be to verify that uploaded files only support certain formats(PDF, JPG, PNG etc). This will make sure that malicious files don’t infect the server.
Question and understand the working of the current code/system before you modify it. Don’t reinvent the wheel, try to use features available in the framework/library before you create a customized solution. Please make sure to scrutinize, understand and use only necessary code when copying code from external sources.
You should ensure that the software performs efficiently using minimal resources. When dealing with large amounts of data, a single extra loop could bog down the server entirely. Ensure that you use the most suitable algorithms for solving commonly occurring problems.
Sensitive data IBNLT API credentials, service/configuration parameters should be saved in a configuration file. This will improve security and make it easier to handle multiple environments.
Also, use constants instead of magic numbers in your code. The expression $age > LEGAL_VOTING_AGE is a lot more understandable than $age > 18.
Always remove unused functions/classes/variables, this makes the code short and more readable. The removed code is not lost, we can restore it using version control software if necessary.
Almost all the object-oriented programming languages offer a form of member visibility in classes. When writing classes always try to make the members as private as possible, which is the most restrictive visibility. This will make the classes more encapsulated and will allow us to change the internals without affecting other classes.
Avoid any unnecessary public methods. It’s easier to make a private method public, but the opposite will be difficult. Removing or renaming public methods is a breaking change, so only add necessary public methods.
Inheritance (IS-A) is not the only way to achieve code reuse. In fact, composition (HAS-A) is a lot more flexible than inheritance in most cases. Composition lets us change the behaviour of a class at runtime.
Inheritance is one of the most misused concepts in object-oriented programming languages. Use inheritance only if the parent and child class share a hierarchical relationship in your business logic. Read more about this here.
The DRY principle states that “Every piece of knowledge must have a single, unambiguous, authoritative representation within a system”. This is about avoiding duplicate code, which forces you to make parallel modifications for every update.
When you find yourself writing code that is similar to something you’ve written before, take a moment to think about what you’re doing and don’t repeat yourself.
Following coding conventions will help us to improve the code readability and to reduce the cost of software maintenance. PSR-12 is the recommended coding convention for PHP and PEP 8 can be followed by Python developers.
Dependency injection is a great technique for achieving separation of concerns when developing software. Use it at all times when you write a class that has external dependencies.
The class dependencies passed as the method arguments shouldn’t be optional, instead use the Null object pattern when you don’t have to use a dependency. This will avoid a lot of null checks and unexpected bugs. Example code is given here.
SOLID is a set of principles that promote software maintainability and reusability. These principles guide us on the arrangement of functions and data structures into classes and also how to interconnect those classes.
The principles are Single responsibility principle, Open/Closed principle, Liskov substitution principle, Interface segregation principle and Dependency inversion principle. Understanding and following them will make your code meet all the above-mentioned desirable qualities. Read more about SOLID principles here.
The law of Demeter or principle of least knowledge is a guideline that states “Only talk to your friends”. This means that an object should know very little about the structure or properties of any other objects it operates on. Read more about this guideline here.
Fully-fledged frameworks like Laravel are so convenient that sometimes it lets developers forget the deep architectural concepts. Sometimes they even go to the lengths to encourage you to not learn them. This is such an example from the official Laravel documentation.
Frameworks are there for improving our productivity and establishing rapid application development, as a developer it’s still important to understand underlying concepts and design decisions to make yourself more valuable.
Password hashing, prevention of injection attacks such as XSS, SQL injection are some areas developers often overlook because the frameworks handle them transparently. Do not fall for this trap, and always make an effort to understand the concepts behind the frameworks you use.
2004 - 2026 © LiteBreeze AB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}